Reference diagram
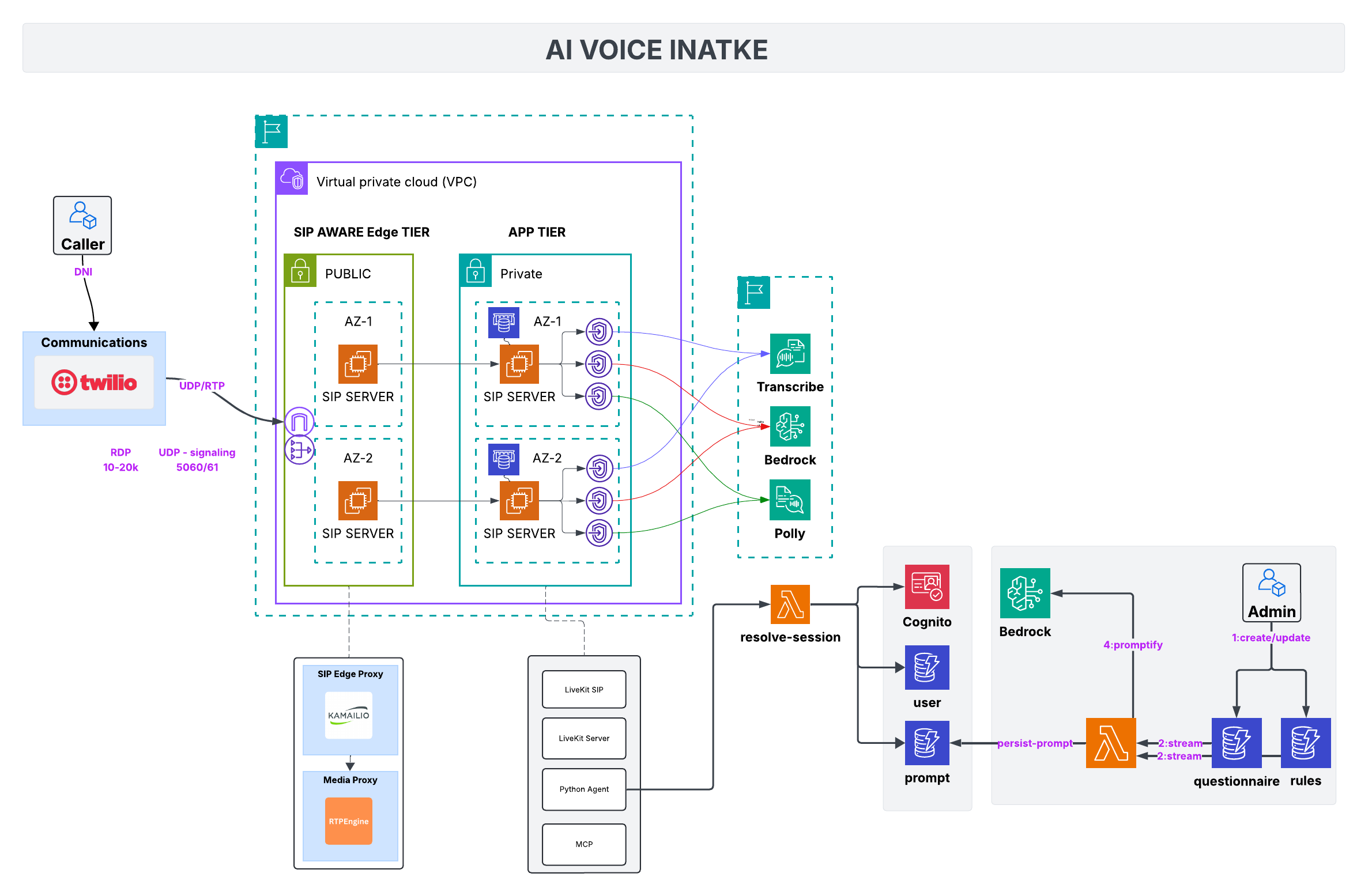
The network is one VPC split into two domains:
- SIP-aware edge tier (public subnets): Kamailio + RTP Engine stack that terminates Twilio’s UDP/RTP, enforces allowlists, and keeps redundant SIP servers online across AZs.
- App tier (private subnets): LiveKit servers, Redis (ElastiCache or EC2), Python agent, MCP tooling, and the speech/LLM pipeline (Transcribe, Bedrock, Polly).
SIP-aware edge tier
What it does
Handles UDP signaling on 5060/61 and wide RTP media ports (10–20k). Each AZ has a SIP server pair behind Kamailio; RTP Engine anchors media so we can record, fork, or rewrite streams before they reach the private tier.
Why public
Carriers need routable IPs. The edge tier is the only part of the deployment exposed to the internet. It rate-limits, enforces verified caller allowlists, and gives us deterministic failover without ever exposing app-tier hosts.
App tier
LiveKit cluster
SIP edge forwards traffic into private AZs where LiveKit SIP + LiveKit Server sit alongside the Python agent. LiveKit keeps real-time media sessions stable while exposing WebRTC hooks for the AI stack.
State + tooling
Redis stores session state. Custom MCP server facilitates AI to interact with your backend.
Silero VAD gates barge-in detection and keeps audio snippets tight before they hit STT.
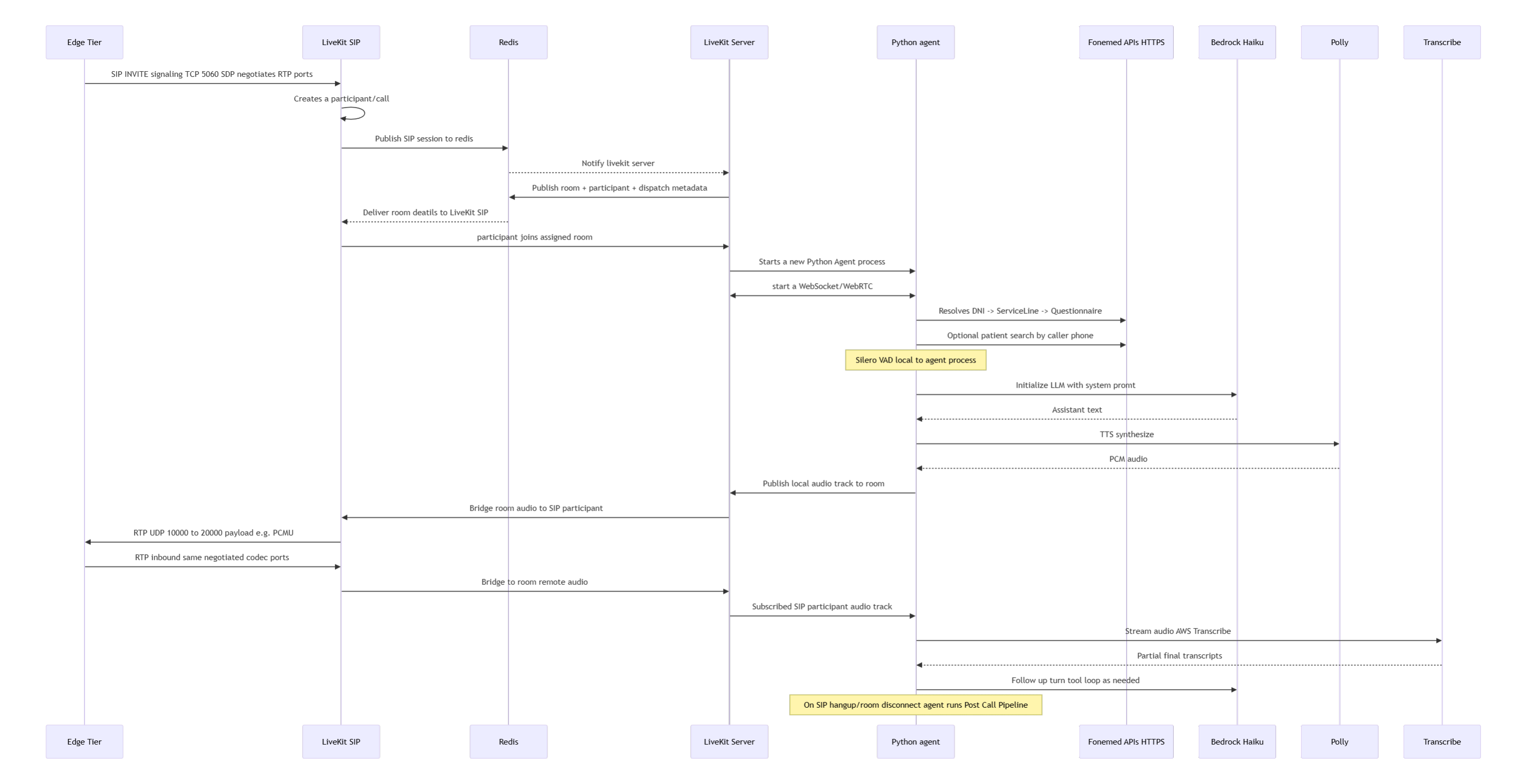
STT → LLM → TTS pipeline
- Amazon Transcribe: Streams speech to text with timestamps, handing interim text to the agent.
- Bedrock (Claude or similar): Receives transcripts plus tools (OpenSearch, questionnaire rules). Prompts define intake order, red-flag detection, and what to log.
- Amazon Polly: Speaks the response back down the LiveKit channel.
Keeping these services separate keeps every tool call auditable. We log prompts, function payloads, and responses for compliance.
Why STT→LLM→TTS pipeline over Speech to Speech Modals like Nova Sonic?
While Speech-to-Speech models like Nova Sonic are emerging and designed for low-latency interactions, they are still lack the intelligence and resoning capabilities required for complex enterprise voice intake scenarios.
By choosing a modular STT → LLM → TTS pipeline, we can leverage best-in-class services for each step. Also LLMs like claude, ChatGPT have faster rate of improvement with new releases unlike niche modals like Nova Sonic. So it makes sense to rely on a modular architecture where you can swap in and out best LLMS as needed.
Putting it together
- Caller hits Twilio → SIP edge. Kamailio checks allowlists and keeps redundant paths per AZ.
- Edge forwards to LiveKit SIP in private subnets. LiveKit proxies audio to Transcribe.
- Transcribe text + context go to Bedrock; tool calls fan out to OpenSearch/Florizel.
- Bedrock response is spoken via Polly, routed back over LiveKit.
- Redis stores state; S3 keeps transcripts; Lambda automation enriches results for downstream systems.
The edge absorbs networking pain (UDP ranges, failover). The app tier stays private, pure AWS. Everything in between is just wiring.
Call Flow: STT → LLM → TTS